2026
-

-
Implicit Bias of SGD in Multivariate ReLU Networks: Effective Width Collapse
Shuang Liang, Tom Jacobs and Guido Montufar
Arxiv (2026)
ABSTRACT BIB
We study the implicit bias of noisy stochastic gradient descent in training wide two-layer ReLU networks for multivariate regression. In a mean-field regime, the training dynamics are approximated by a Wasserstein gradient flow that converges to a unique stationary measure. We characterize the structure of this stationary measure and the predictor it represents. We show that, despite the network being infinitely overparameterized, the learned predictor admits an effectively finite representation: the input weights and biases align along finitely many directions, leading to an effective width collapse. In particular, the solution function is continuous piecewise affine, with affine regions determined by the cells of a finite hyperplane arrangement. The number of learned directions, and hence hyperplanes, is bounded above by 2P−1, where P denotes the number of linear dichotomies realizable on the training inputs. We further establish a non-redundancy property of the learned representation by proving that each learned direction induces a unique ternary activation pattern on the training data. Consequently, the complexity of the learned predictor is governed by the combinatorial geometry of the training data.@inproceedings{Liang2026ImplicitBO, title={Implicit Bias of SGD in Multivariate ReLU Networks: Effective Width Collapse}, author={Shuang Liang and Tom Jacobs and Guido Mont{\'u}far}, year={2026}, url={https://api.semanticscholar.org/CorpusID:289934596} }
-
-
Implicit Bias of Mirror Flow in Homogeneous Neural Networks: Sparse and Dense Feature Learning
Tom Jacobs and Guido Montufar
Arxiv (2026)
ABSTRACT BIB
We study the max-margin solutions reached by mirror flow in deep neural networks with homogeneous activation functions. Extending classical results on gradient flow, we derive a novel balance equation for mirror flow from convex duality, enabling a characterization of the horizon function governing the induced margin. We further establish max-margin characterizations together with convergence rates and norm growth estimates. Finally, we support our theory through experiments on synthetic datasets and standard vision tasks. Concretely, we show that: (1) distinct non-homogeneous mirror maps can induce the same max-margin solution; (2) convergence can be extremely slow, including exponentially slow regimes; and (3) although all considered mirror maps exhibit feature learning, they can produce markedly different representations, ranging from sparse to dense neuron activations. Together, these results provide a unified perspective on sparse and dense feature learning in homogeneous neural networks, highlighting how mirror maps shape both optimization dynamics and the geometry of the learned classifiers.@misc{jacobs2026implicitbiasmirrorflow, title={Implicit Bias of Mirror Flow in Homogeneous Neural Networks: Sparse and Dense Feature Learning}, author={Tom Jacobs and Guido Montufar}, year={2026}, eprint={2605.19458}, archivePrefix={arXiv}, primaryClass={cs.LG}, url={https://arxiv.org/abs/2605.19458}, }
-
-
HORST: Composing Optimizer Geometries for Sparse Transformer Training
Tom Jacobs, Rohan Jain, and Rebekka Burkholz
HiLD at ICML 2026 Poster (2026)
ABSTRACT BIB
Sparsifying transformers remains a fundamental challenge, as standard optimizers fail to simultaneously encourage sparsity and maintain training stability. Effective adaptive optimizers exhibit an implicit L_infty bias favoring stability, yet, sparsity requires an L_1 bias. To integrate sparsity, we propose a composition of optimizer steps, which we cast as non-commutative operators to analyze and combine their optimization geometry in a principled way. This yields HORST (Hyperbolic Operator for Robust Sparse Training), a modular optimizer that inherits stability from adaptive methods while inducing L_1 sparsity bias through a hyperbolic mirror map. Our experiments demonstrate its utility for sparse training of transformers on both vision and language tasks. HORST consistently and significantly outperforms AdamW baselines across all sparsity levels, with large gains at higher sparsity.@inproceedings{ jacobs2026horst, title={{HORST}: Composing Optimizer Geometries for Sparse Transformer Training}, author={Tom Jacobs and Rohan Jain and Rebekka Burkholz}, booktitle={High-dimensional Learning Dynamics 2026}, year={2026}, url={https://openreview.net/forum?id=fSQw4Puobo} }
-
-
Continuous Sparsification via Minimizing Movement
Hoang Pham, Tom Jacobs, Binh Nguyen, Rebekka Burkholz and Long Tran-Thanh
HiLD at ICML 2026 Poster (2026)
ABSTRACT BIB
Continuous sparsification is a popular approach for finding efficient sparse subnetworks, optimizing soft masks before applying a hard Top- projection. However, existing methods typically regularize mask variables using flat Euclidean geometry, penalizing local rewirings and disruptive long-range relocations equally. To address this, we propose Continuous Sparsification via Minimizing Movement (CSMM), a geometry-aware framework that treats layer connectivity as a probability allocation on the simplex. By leveraging the minimizing-movement scheme, we regularize the temporal evolution of connectivity using flexible proximal penalty functions. This approach decouples task performance from structural evolution, allowing practitioners to impose specific geometric inductive biases on topology evolution. The experiment shows a promising result on CIFAR10 dataset under ResNet 20 architecture, offering a new approach on continuous sparsification.@inproceedings{ pham2026continuous, title={Continuous Sparsification via Minimizing Movement}, author={Hoang Pham and Tom Jacobs and Binh Nguyen and Rebekka Burkholz and Long Tran-Thanh}, booktitle={High-dimensional Learning Dynamics 2026}, year={2026}, url={https://openreview.net/forum?id=nsSLDnJ2uU} }
-
-
SparseOpt: Addressing Normalization-induced Gradient Skew in Sparse Training
Mohammed Adnan, Rohan Jain, Tom Jacobs, Ekansh Sharma, Rahul G Krishnan, Rebekka Burkholz, and Yani Ioannou
ICML (2026)
ABSTRACT BIB
Dynamic Sparse Training (DST) methods train neural networks by maintaining sparsity while dynamically adapting the network topology. Despite the promise of reduced computation, DST methods converge significantly slower than dense training, often requiring comparable training time to achieve similar accuracy. We demonstrate both analytically and empirically that Batch Normalization (BN) adversely affects sparse training, and propose SparseOpt — a sparsity-aware optimizer — to address this. Experiments on ResNet models across CIFAR-100 and ImageNet demonstrate consistently faster convergence and improved generalization with our proposed method. Our work highlights the limitations of current normalization layers in sparse training and provides the first systematic study of the interaction between Batch Normalization, sparse layers, and DST, taking a significant step toward making DST practically competitive with dense training.@inproceedings{ adnan2026sparseopt, title={SparseOPt: Addressing Normalization-induced Gradient Skew in Sparse Training}, author={Mohammed Adnan and Rohan Jain and Tom Jacobs and Ekansh Sharma and Rahul G Krishnan and Rebekka Burkholz, and Yani Ioannou}, booktitle={Forty-third International Conference on Machine Learning}, year={2026}, url={https://openreview.net/forum?id=o9JP7N8YO9} }
-
-
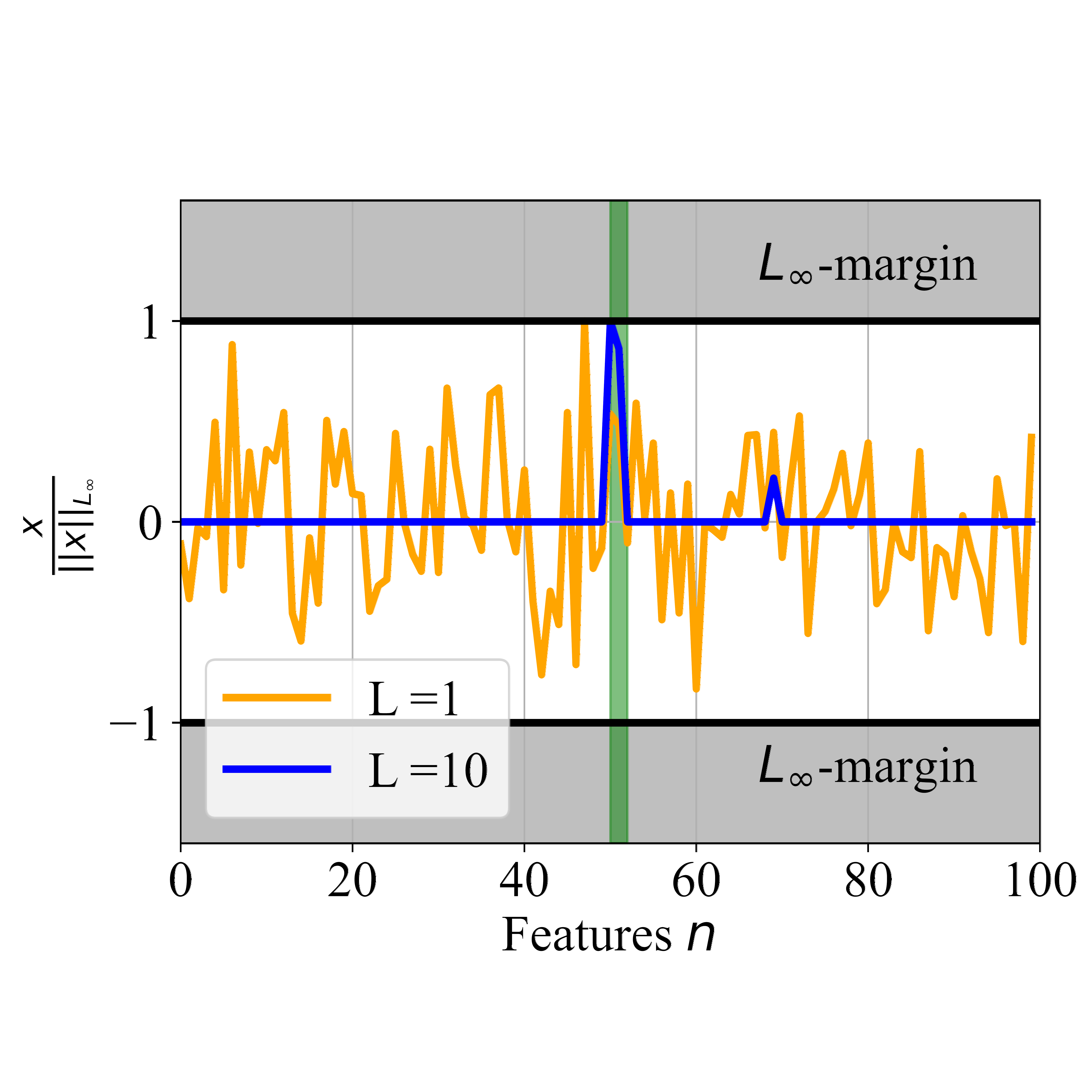
Never Saddle for Reparameterized Steepest Descent as Mirror Flow
Tom Jacobs, Chao Zhou, and Rebekka Burkholz
ICLR (2026)
ABSTRACT BIB
What distinguishes modern adaptive methods from gradient descent to favor better generalizing solutions? To study this question for steepest-descent methods, including sign descent (an optimizer closely related to Adam), we introduce steepest mirror flows as a unifying theoretical framework. This enables us to analyze how optimization geometry governs learning dynamics, implicit bias, and sparsity. It also suggests a mechanism that may help explain why Adam and AdamW often outperform SGD in fine-tuning. Focusing on diagonal linear networks and deep diagonal linear reparameterizations, we show that steeper descent promotes saddle-point escape. By contrast, gradient descent typically requires much larger learning rates to escape saddles—regimes that are less common in fine-tuning practice. Furthermore, we find that decoupled weight decay, as in AdamW, stabilizes sparse training by enforcing novel balance equations. Empirical experiments establish that our theoretical insights and hypothesized mechanisms transfer to realistic settings. Together, these results identify two mechanisms through which steepest descent can benefit modern optimization: saddle escape and sparsity.@inproceedings{ Jacobs2026never, title={Never Saddle for Reparameterized Steepest Descent as Mirror Flow}, author={Tom Jacobs and Chao Zhou and Rebekka Burkholz}, booktitle={The Fourteenth International Conference on Learning Representations}, year={2026}, url={https://openreview.net/forum?id=YgudIlQ9nC} }
-
-
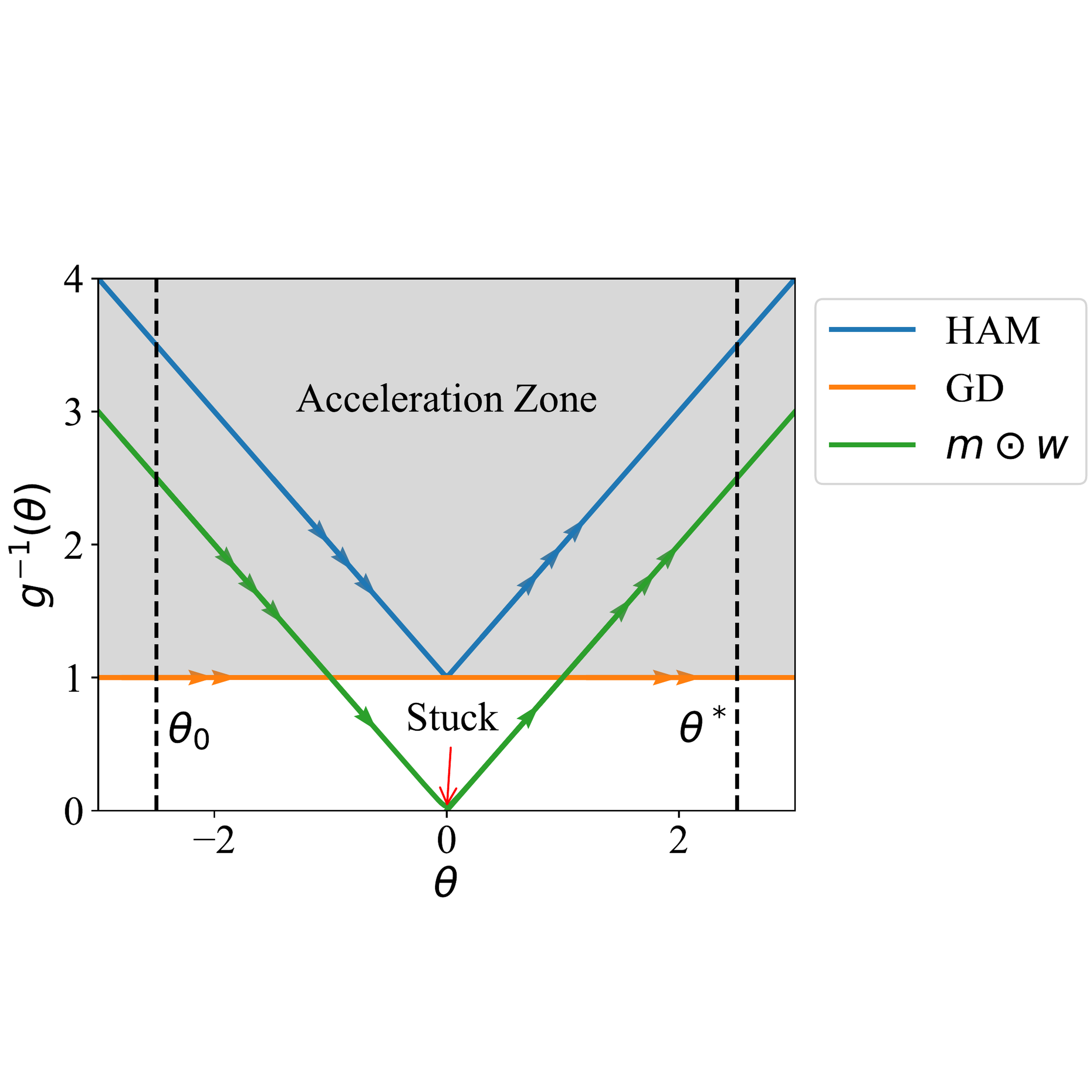
Hyperbolic Aware Minimization: Implicit Bias for Sparsity
Tom Jacobs, Advait Gadhikar, Celia Rubio-Madrigal, and Rebekka Burkholz
ICLR (2026)
ABSTRACT BIB
Understanding the implicit bias of optimization algorithms is key to explaining and improving the generalization of deep models. The hyperbolic implicit bias induced by pointwise overparameterization promotes sparsity, but also yields a small inverse Riemannian metric near zero, slowing down parameter movement and impeding meaningful parameter sign flips. To overcome this obstacle, we propose Hyperbolic Aware Minimization (HAM), which alternates a standard optimizer step with a lightweight hyperbolic mirror step. The mirror step incurs less compute and memory than pointwise overparameterization, reproduces its beneficial hyperbolic geometry for feature learning, and mitigates the small–inverse-metric bottleneck. Our characterization of the implicit bias in the context of underdetermined linear regression provides insights into the mechanism how HAM consistently increases performance extemdash even in the case of dense training, as we demonstrate in experiments with standard vision benchmarks. HAM is especially effective in combination with different sparsification methods, advancing the state of the art.@inproceedings{ jacobs2025ham, title={Hyperbolic Aware Minimization: Implicit Bias for Sparsity}, author={Tom Jacobs and Advait Gadhikar and Celia Rubio-Madrigal and Rebekka Burkholz}, booktitle={The Fourteenth International Conference on Learning Representations}, year={2026}, url={https://openreview.net/forum?id=XKB5Hu0ACY} }
2025
-
-
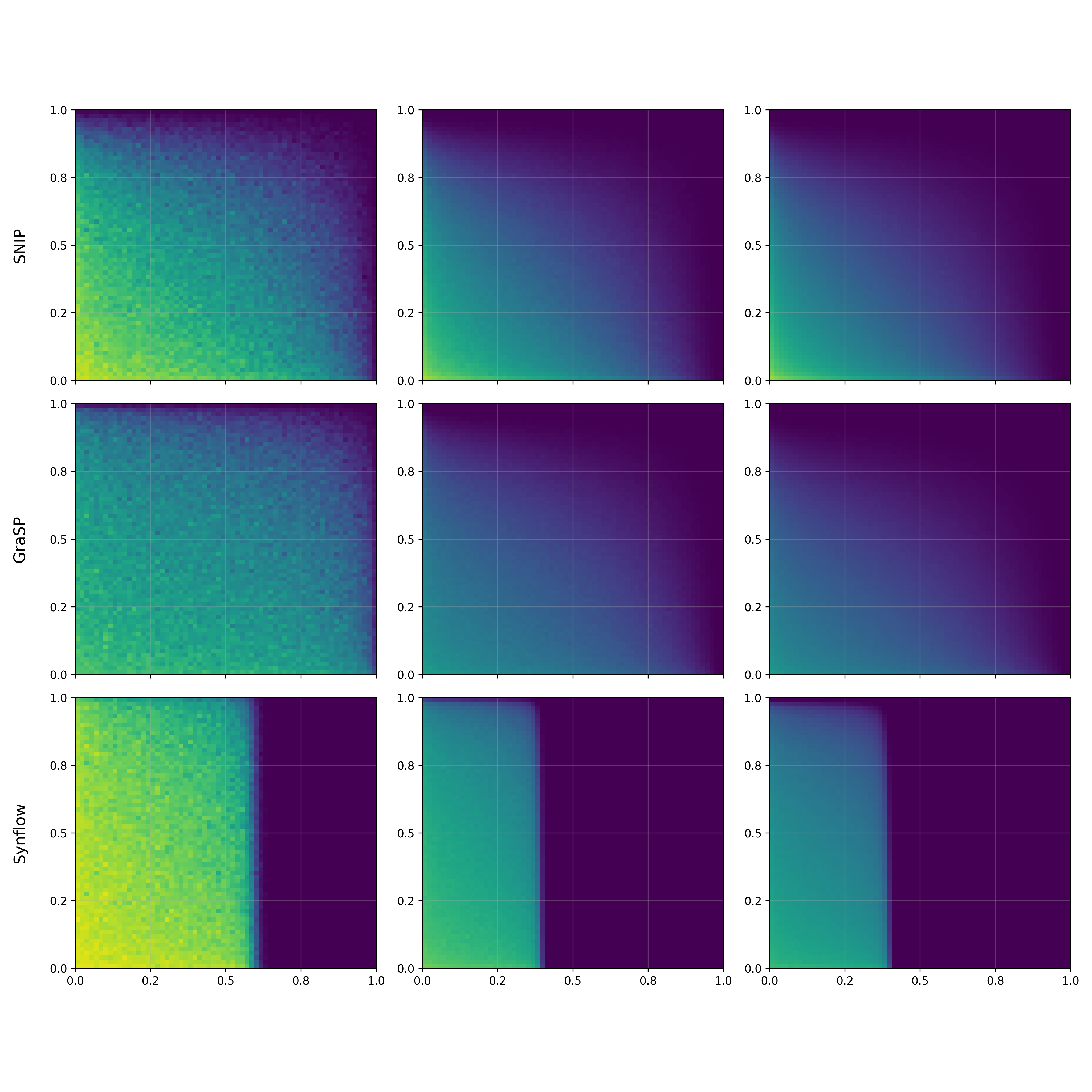
The Graphon Limit Hypothesis: Understanding Neural Network Pruning via Infinite Width Analysis
Hoang Pham, The-Anh Ta, Tom Jacobs, Rebekka Burkholz and Long Tran-Thanh
NeurIPS (2025)
ABSTRACT BIB
Sparse neural networks promise efficiency, yet training them effectively remains a fundamental challenge. Despite advances in pruning methods that create sparse architectures, understanding why some sparse structures are better trainable than others with the same level of sparsity remains poorly understood. Aiming to develop a systematic approach to this fundamental problem, we propose a novel theoretical framework based on the theory of graph limits, particularly graphons, that characterizes sparse neural networks in the infinite-width regime. Our key insight is that connectivity patterns of sparse neural networks induced by pruning methods converge to specific graphons as networks' width tends to infinity, which encodes implicit structural biases of different pruning methods. We postulate the Graphon Limit Hypothesis and provide empirical evidence to support it. Leveraging this graphon representation, we derive a Graphon Neural Tangent Kernel (Graphon NTK) to study the training dynamics of sparse networks in the infinite width limit. Graphon NTK provides a general framework for the theoretical analysis of sparse networks. We empirically show that the spectral analysis of Graphon NTK correlates with observed training dynamics of sparse networks, explaining the varying convergence behaviours of different pruning methods. Our framework provides theoretical insights into the impact of connectivity patterns on the trainability of various sparse network architectures.@inproceedings{ anonymous2025the, title={The Graphon Limit Hypothesis: Understanding Neural Network Pruning via Infinite Width Analysis}, author={Anonymous}, booktitle={The Thirty-ninth Annual Conference on Neural Information Processing Systems}, year={2025}, url={https://openreview.net/forum?id=EEZLBhyer1} }
-
-
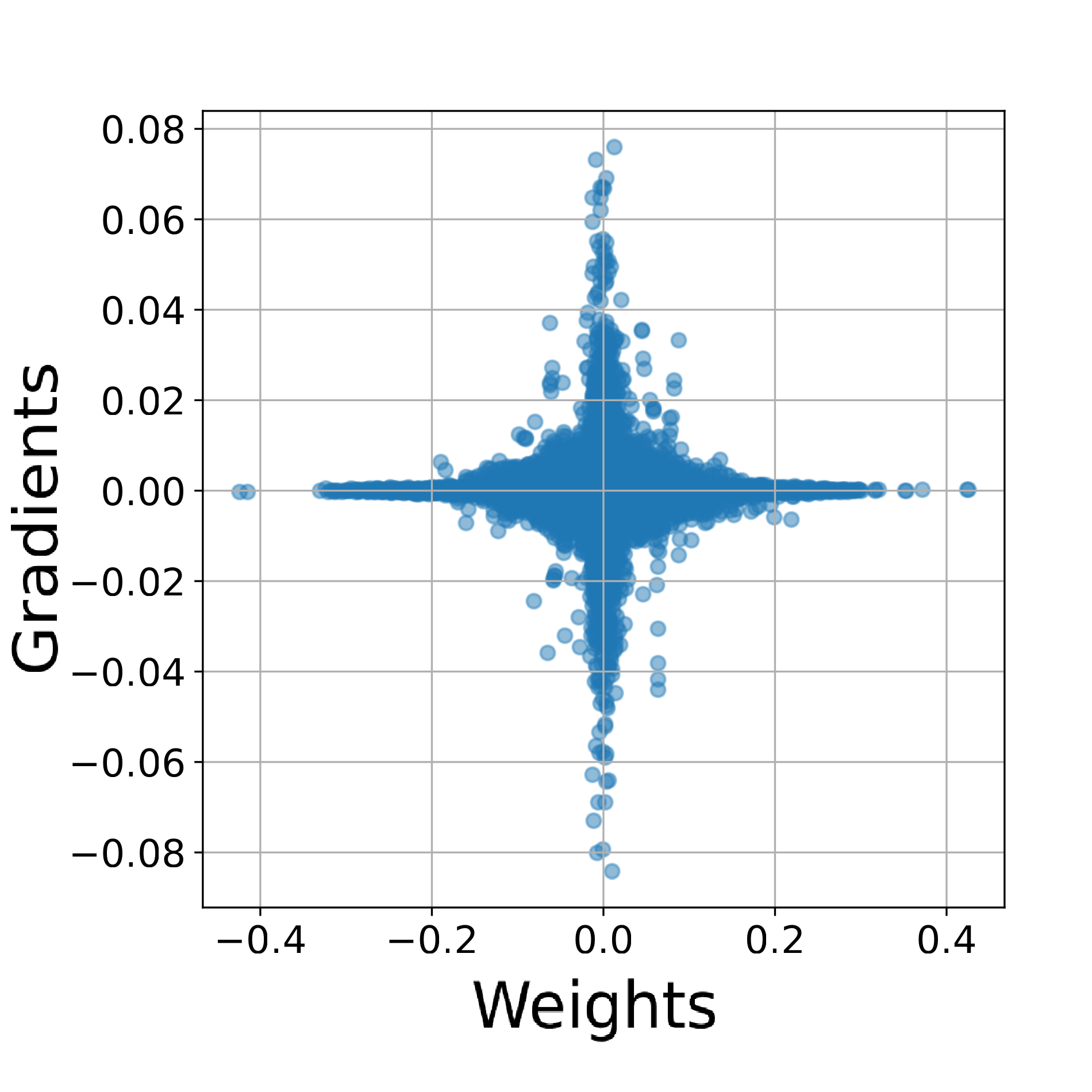
Pay Attention to Small Weights
Chao Zhou, Tom Jacobs, Advait Gadhikar, and Rebekka Burkholz
NeurIPS (2025)
ABSTRACT BIB
Finetuning large pretrained neural networks is known to be resource-intensive, both in terms of memory and computational cost. To mitigate this, a common approach is to restrict training to a subset of the model parameters. By analyzing the relationship between gradients and weights during finetuning, we observe a notable pattern: large gradients are often associated with small-magnitude weights. This correlation is more pronounced in finetuning settings than in training from scratch. Motivated by this observation, we propose NANOADAM, which dynamically updates only the small-magnitude weights during finetuning and offers several practical advantages: first, this criterion is gradient-free -- the parameter subset can be determined without gradient computation; second, it preserves large-magnitude weights, which are likely to encode critical features learned during pretraining, thereby reducing the risk of catastrophic forgetting; thirdly, it permits the use of larger learning rates and consistently leads to better generalization performance in experiments. We demonstrate this for both NLP and vision tasks.@inproceedings{ zhou2025payattentionsmallweights, title={Pay Attention to Small Weights}, author={Chao Zhou and Tom Jacobs and Advait Gadhikar and Rebekka Burkholz}, booktitle={The Thirty-ninth Annual Conference on Neural Information Processing Systems}, year={2025}, url={https://openreview.net/forum?id=XKnOA7MhCz} }
-
-
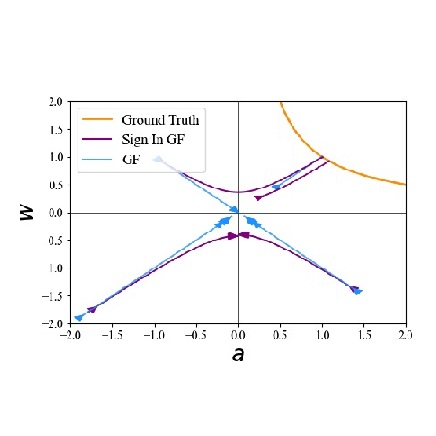
Sign-In to the Lottery: Reparameterizing Sparse Training
Advait Gadhikar*, Tom Jacobs*, Chao Zhou, and Rebekka Burkholz
NeurIPS (2025)
ABSTRACT BIB
The performance gap between training sparse neural networks from scratch (PaI) and dense-to-sparse training presents a major roadblock for efficient deep learning. According to the Lottery Ticket Hypothesis, PaI hinges on finding a problem specific parameter initialization. As we show, to this end, determining correct parameter signs is sufficient. Yet, they remain elusive to PaI. To address this issue, we propose Sign-In, which employs a dynamic reparameterization that provably induces sign flips. Such sign flips are complementary to the ones that dense-to-sparse training can accomplish, rendering Sign-In as an orthogonal method. While our experiments and theory suggest performance improvements of PaI, they also carve out the main open challenge to close the gap between PaI and dense-to-sparse training.@inproceedings{ Gadhikar2025SignInTT, title={Sign-In to the Lottery: Reparameterizing Sparse Training}, author={Advait Gadhikar and Tom Jacobs and Chao Zhou and Rebekka Burkholz}, booktitle={The Thirty-ninth Annual Conference on Neural Information Processing Systems}, year={2025}, url={https://openreview.net/forum?id=iwKT7MEZZw} }
-
-
Mirror, Mirror of the Flow: How Does Regularization Shape Implicit Bias?
Tom Jacobs, Chao Zhou, and Rebekka Burkholz
ICML (2025)
ABSTRACT BIB
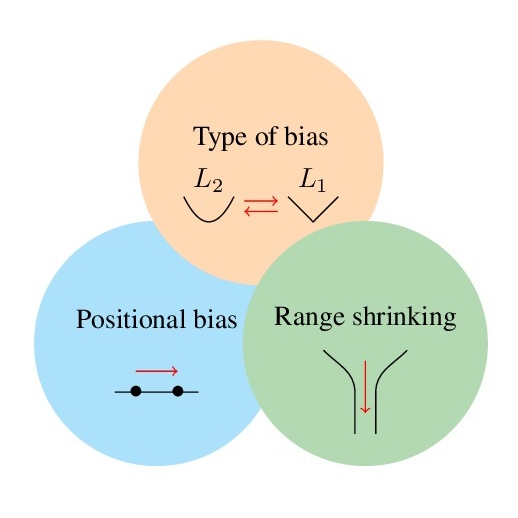
Implicit bias plays an important role in explaining how overparameterized models generalize well. Explicit regularization like weight decay is often employed in addition to prevent overfitting. While both concepts have been studied separately, in practice, they often act in tandem. Understanding their interplay is key to controlling the shape and strength of implicit bias, as it can be modified by explicit regularization. To this end, we incorporate explicit regularization into the mirror flow framework and analyze its lasting effects on the geometry of the training dynamics, covering three distinct effects: positional bias, type of bias, and range shrinking. Our analytical approach encompasses a broad class of problems, including sparse coding, matrix sensing, single-layer attention, and LoRA, for which we demonstrate the utility of our insights. To exploit the lasting effect of regularization and highlight the potential benefit of dynamic weight decay schedules, we propose to switch off weight decay during training, which can improve generalization, as we demonstrate in experiments.@inproceedings{ jacobs2025mirror, title={Mirror, Mirror of the Flow: How Does Regularization Shape Implicit Bias?}, author={Tom Jacobs and Chao Zhou and Rebekka Burkholz}, booktitle={Forty-second International Conference on Machine Learning}, year={2025}, url={https://api.semanticscholar.org/CorpusID:277857621} }
-
-
Mask in the Mirror: Implicit Sparsification
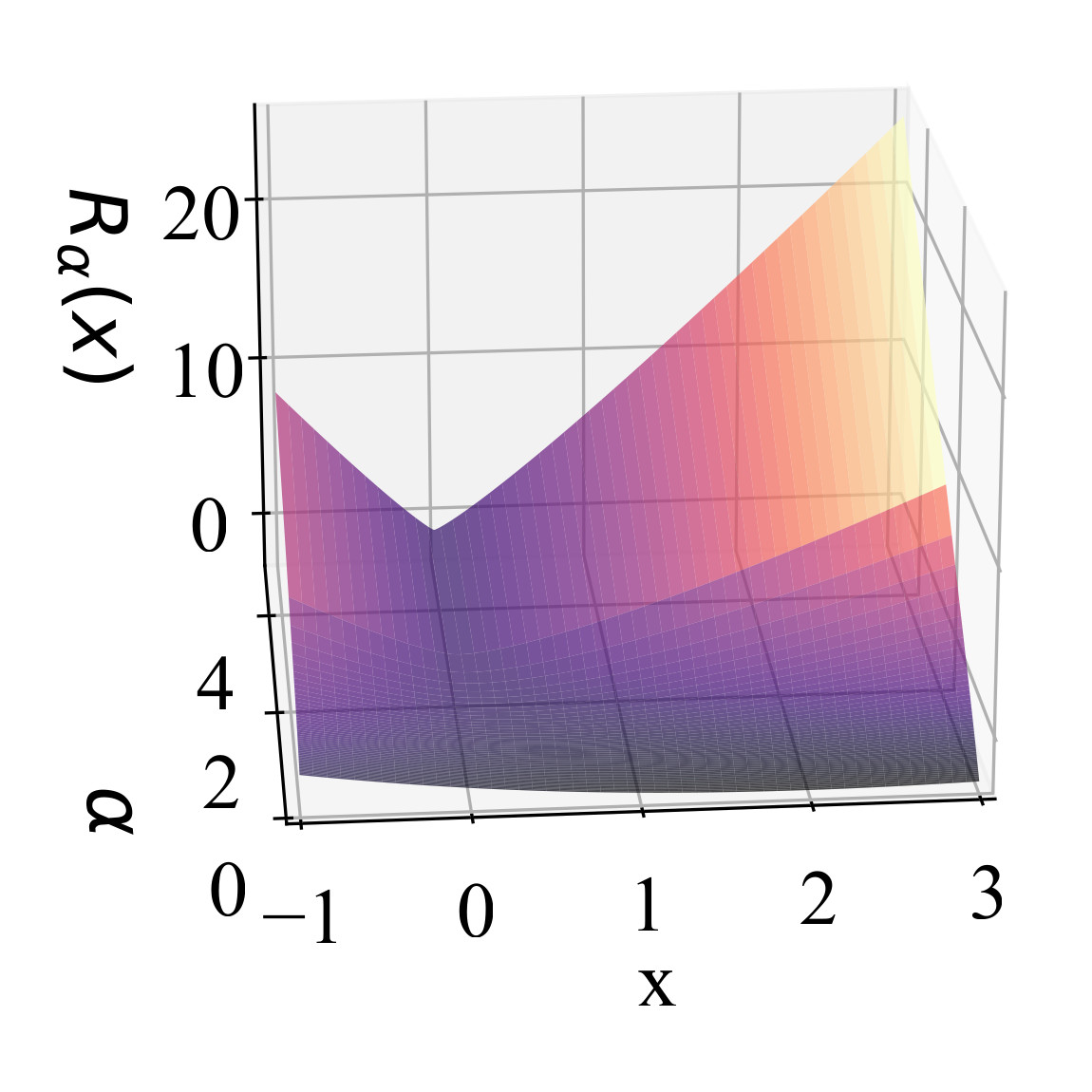
Tom Jacobs and Rebekka Burkholz
ICLR (2025)
ABSTRACT BIB
Continuous sparsification strategies are among the most effective methods for reducing the inference costs and memory demands of large-scale neural networks. A key factor in their success is the implicit L1 regularization induced by jointly learning both mask and weight variables, which has been shown experimentally to outperform explicit L1 regularization. We provide a theoretical explanation for this observation by analyzing the learning dynamics, revealing that early continuous sparsification is governed by an implicit L2 regularization that gradually transitions to an L1 penalty over time. Leveraging this insight, we propose a method to dynamically control the strength of this implicit bias. Through an extension of the mirror flow framework, we establish convergence and optimality guarantees in the context of underdetermined linear regression. Our theoretical findings may be of independent interest, as we demonstrate how to enter the rich regime and show that the implicit bias can be controlled via a time-dependent Bregman potential. To validate these insights, we introduce PILoT, a continuous sparsification approach with novel initialization and dynamic regularization, which consistently outperforms baselines in standard experiments.@inproceedings{ jacobs2025mask, title={Mask in the Mirror: Implicit Sparsification}, author={Tom Jacobs and Rebekka Burkholz}, booktitle={The Thirteenth International Conference on Learning Representations}, year={2025}, url={https://openreview.net/forum?id=U47ymTS3ut} }